從文集中抽取隱藏「主題」thematic structures 的技術方法,LDA (Latent Dirichlet allocation) (LDA,潜在狄利克雷分配模型) 模型及其延伸變成了最常用的模型,已經被廣泛用來識別大規模文集(document collection)或語料庫(corpus)中潛藏的主題訊息。
主題模型自動分析每個文檔,統計文檔內的詞語,根據統計的信息來斷定當前文檔含有哪些主題,以及每個主題所占的比例各為多少。LDA遵循貝式機率模型。
P(w|d) = \Sigma p(w|z) * p(z|d)
此model架設一個文本裡有k個主題,一個文檔w有多個topic組成,每一個主題又代表了很多單詞所構成的一個機率分佈。
生成文檔的方式:把topic看為一個詞的分布,把標籤看為了一個topic,從而建立一個機率模型,用數據去訓練得到參數。對於文集中的每一篇文檔,先抽取一個topics proportion (theta);然後對於這個文檔中的每一個詞的位置 wi, LDA 先從theta中選擇一個topic,然後再從這個topic對應的詞分布中選擇一個詞去填充;按照上述步驟直到整個文檔集合產生完畢。示意圖如下:
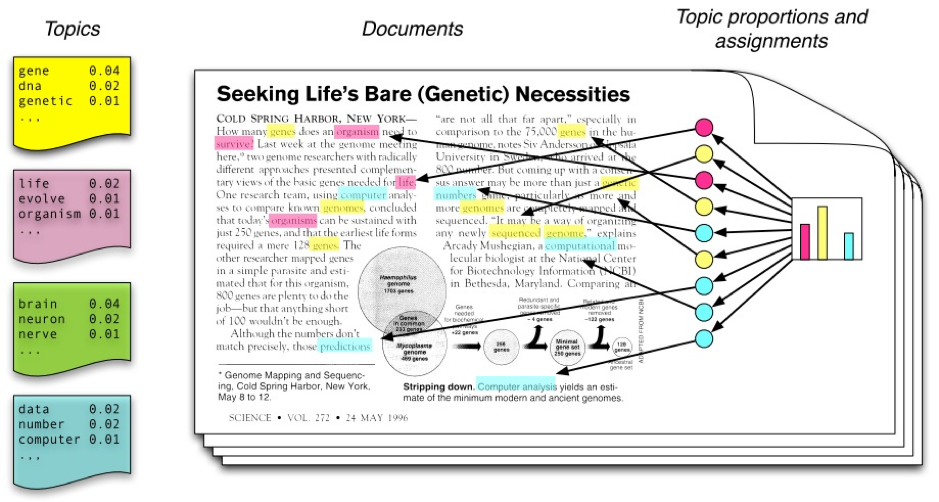
最左邊顯示每個主題下都有一些容易出現的詞,在此每一個詞在這個topic下都有一個出現的機率。右邊的直條圖顯示一篇文章由不同的主題組成,各自站了不同比率。
透過圖示能更容易理解產生文章的過程,從右邊主題集合中按機率分布選取一些主題,接著從每一個主題中按機率分布選取詞語,這些詞語構成了最終的文檔,詞語的敘述在此模型是無關的,可看成一個bag-of-words。
參考來源
主題模型 Topic Modeling
https://loperntu.gitbooks.io/ladsbook/content/topic-modeling.html
主題模型Topic Model知識資料全集(基礎/進階/論文/綜述/代碼/專家,附PDF下載)
https://hk.saowen.com/a/15f4d3523881312a39e505ff24b89610ca140a0d806dee61a911b094c2e64d05
Topic Model的分類和設計原則
https://read01.com/zh-tw/oO2LoJ.html#.W97UyGQzYk8

